Abstract
We present HuMoCon, a novel motion-video understanding framework designed for advanced human behavior analysis. The core of our method is a human motion concept discovery framework that efficiently trains multi-modal encoders to extract semantically meaningful and generalizable features. HuMoCon addresses key challenges in motion concept discovery, including explicit cross-modal feature alignment and preserving high-frequency information via velocity reconstruction. Comprehensive experiments on standard benchmarks demonstrate that HuMoCon significantly outperforms state-of-the-art methods in human motion understanding.
Overview

HuMoCon introduces a novel approach to human motion understanding through automated concept discovery. Our framework identifies meaningful motion concepts and their relationships, enabling more interpretable and effective human behavior analysis.
Method
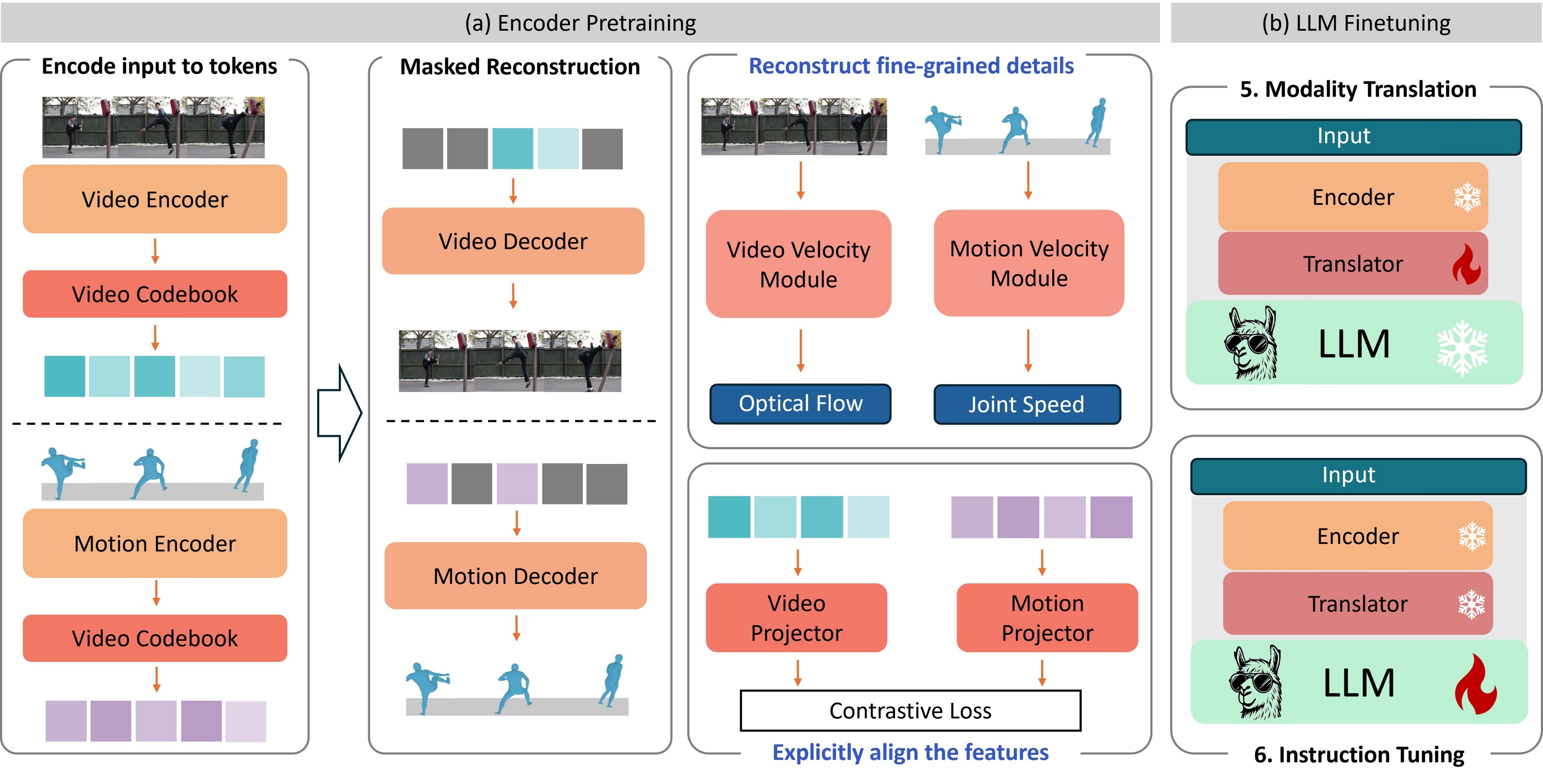
Our method consists of three main components: (1) Motion Encoder that processes raw motion sequences, (2) Concept Discovery Module that identifies semantic concepts via VQ-VAE-based discretization with masked and velocity reconstruction objectives, and (3) Concept Reasoning Module that establishes relationships between discovered concepts for comprehensive understanding. We explicitly align video and motion features during encoder pre-training and leverage LLM fine-tuning for downstream motion-video question answering tasks.
Experiments
Quantitative Results
BABEL-QA Benchmark
| Model | Pred type | Overall | Action | Direction | BodyPart | Before | After | Other |
|---|---|---|---|---|---|---|---|---|
| 2s-AGCN-M | cls. | 0.355 | 0.384 | 0.352 | 0.228 | 0.331 | 0.264 | 0.295 |
| 2s-AGCN-R | cls. | 0.357 | 0.396 | 0.352 | 0.194 | 0.337 | 0.301 | 0.285 |
| MotionCLIP-M | cls. | 0.430 | 0.485 | 0.361 | 0.272 | 0.372 | 0.321 | 0.404 |
| MotionCLIP-R | cls. | 0.420 | 0.489 | 0.310 | 0.250 | 0.398 | 0.314 | 0.387 |
| MotionLLM | gen. | 0.436 | 0.517 | 0.354 | 0.154 | 0.427 | 0.368 | 0.529 |
| Ours | gen. | 0.711 | 0.809 | 0.697 | 0.623 | 0.707 | 0.635 | 0.797 |
Our method outperforms baselines by a large margin on the BABEL-QA test set, achieving 0.711 overall accuracy compared to 0.436 by MotionLLM, with notable gains in BodyPart queries (0.623 vs. 0.154).
ActivityNet-QA Benchmark
| Model | Acc↑ | Score↑ |
|---|---|---|
| FrozenBiLM | 24.7 | - |
| VideoChat | - | 2.2 |
| LLaMA-Adapter | 34.2 | 2.7 |
| Video-LLaMA | 12.4 | 1.1 |
| Video-ChatGPT | 35.2 | 2.7 |
| Video-LLaVA | 45.3 | 3.3 |
| VideoChat2 | 49.1 | 3.3 |
| MotionLLM | 53.3 | 3.5 |
| Ours | 54.2 | 3.6 |
On ActivityNet-QA, HuMoCon achieves 54.2% accuracy and a score of 3.6, outperforming previous methods including MotionLLM (53.3%, 3.5).
Ablation Study
BABEL-QA Ablation
| Model | Pred type | Overall | Action | Direction | BodyPart | Before | After | Other |
|---|---|---|---|---|---|---|---|---|
| MotionLLM | gen. | 0.436 | 0.517 | 0.354 | 0.154 | 0.427 | 0.368 | 0.529 |
| Ours-w/oLrec | gen. | 0.696 | 0.741 | 0.645 | 0.577 | 0.600 | 0.597 | 0.762 |
| Ours-w/oLdis&Lact | gen. | 0.637 | 0.693 | 0.478 | 0.606 | 0.667 | 0.526 | 0.709 |
| Ours-w/oLalign | gen. | 0.675 | 0.743 | 0.579 | 0.523 | 0.584 | 0.570 | 0.743 |
| Ours | gen. | 0.711 | 0.809 | 0.697 | 0.623 | 0.707 | 0.635 | 0.797 |
Ablation confirms that velocity reconstruction and feature alignment are critical for performance; removing these modules degrades results significantly.
Qualitative Results
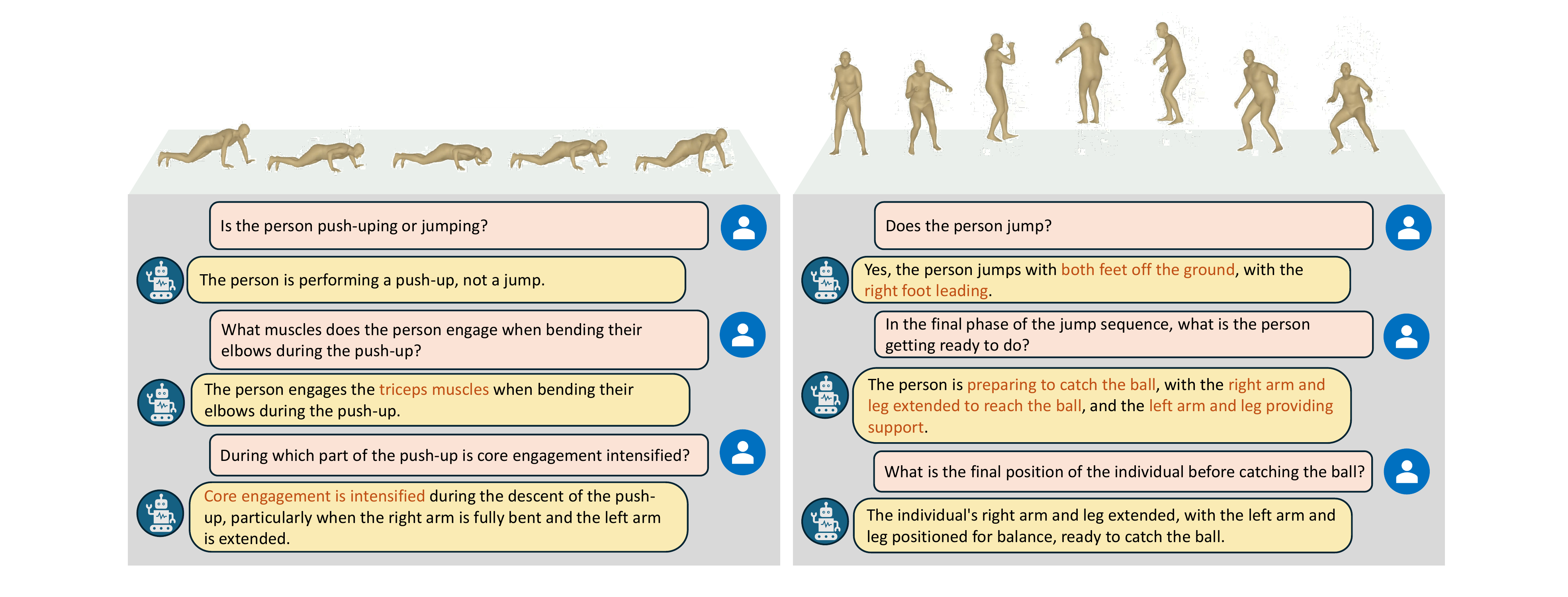
Example Q&A results demonstrate detailed motion understanding, e.g., answering kinematic and contextual questions such as muscle engagement during push-ups and phase descriptions in jump sequences, showing HuMoCon’s capability to reason about motion sequences.
Citation
Acknowledgments
This work is supported by the Early Career Scheme of the Research Grants Council (grant #27207224), the HKU-100 Award, a donation from the Musketeers Foundation, and an Academic Gift from Meta. Data collection, processing, and model development were conducted at The University of Hong Kong.